Introduction to OCR Technology
In today’s digital world, the focus is on converting documents into the required digital format for seamless usage, whether manually or through automation. To automate the offices’ work, there is a need for the most developed solution the most advanced ones among them would be OCR technology. So, what is OCR? OCR stands for Optical Character Recognition, and it is defined as a technology that enables computers to interpret or extract text from images, such as scanned documents or even PDF files. OCR eliminates the tedious task of manually converting printed or handwritten documents into machine-readable text, improving efficiency and reducing errors.
Commonly used among other industries within which management of documents is important are finance, healthcare, retail, logistics, and legal, where OCR serves as automated data entry and invoice extraction in real-time retrieval of information. This post talks about how OCR works, its process, types, uses, algorithms, and what’s in store for the future. Some of the important words in this post include OCR device, OCR scanning, optical character reader, and the function of OCR.
How OCR Works: Understanding the OCR Process
The OCR technique works on multiple processes, proceeding stepwise: scanning, recognising, and editing text from a graphic image.

OCR Scanning
The OCR process starts with OCR scanning, when a document is made into a digital image. This step holds great importance as the quality of the scanned image will define how accurately the text can be recognised. Documents can be scanned via flatbed scanners, mobile cameras, or dedicated OCR devices. Many modern smartphones also come with built-in OCR technology for recognising text in real time.
Image Pre-Processing Enhances Accuracy
Before the recognition of text, the OCR software performs certain operations on the image to properly clarify the image. Pre-processing techniques include binarisation, noise reduction, and skew correction. These techniques are used to increase the accuracy of OCR processes: Binarisation refers to the conversion of images into black and white for better contrast between text and background to help text recognition. Noise reduction is used to clean the image of any unwanted distortions, and skew correction fixes the document alignment. This step will allow free space for the OCR algorithm to accurately recognise the characters.
Text Segmentation and Character Recognition
Once the image is processed, OCR software will identify different text elements, including characters, words, and lines. There are two principal approaches to accomplishing this:
Pattern Recognition-Based OCR compares the scanned text with an internal font and character pattern database.
Feature Extraction-Based OCR identifies features of individual characters, such as edges, curves, and intersections, without matching to stored templates.
OCR Algorithm and Text Conversion
Each character in a segment of text is analysed by various OCR algorithms to convert it into a computer-editable machine format. Artificial intelligence (AI) and machine learning (ML) offer mechanisms through which the software identifies complex fonts, handwritten text, and distorted characters. Modern recognition is accomplished using deep learning training of the OCR devices and software in question, thus enabling their recognition capabilities to improve over time.
Post-Processing and Validation
After the text is extracted, it is then subjected to post-processing methods wherein validation and error correction are done. Sometimes the OCR software performs contextual analysis and applies language models to ascertain spelling and format correctness, thus enhancing the reliability of the output just before export to text editors, spreadsheets, or database systems.
Key Components of an OCR System
One important component of an OCR system is the hardware and software design that collaborate to read text from images.
OCR Scanning Devices
OCR devices are hardware tools that are used for capturing images for text recognition. They may include flatbed scanners, handheld scanners, mobile phone cameras, and industrial OCR readers. Commercial use for large-scale applications mostly involves high-speed document scanners that could process hundreds of pages per minute.
Optical Character Recognition Software
It is the software used to drive the recognition process. It processes scanned images, applies AI-driven OCR algorithms, and extracts editable text. Up to now, some popular examples of OCR software products are Adobe Acrobat OCR, ABBYY FineReader, Tesseract OCR, and Google Cloud Vision OCR. Many enterprises integrate OCR technology into ERP systems, document management platforms, and automation software to ensure smooth workflow management.
Uses of OCR in Various Industries
The many applications of OCR technology are indeed remarkable; they help multiple sectors enhance their functions and decrease manual workload.
Banking and Finance
To use the digital automation of cheques, KYC verification, and financial document management, banks combined with financial institutions implement optical character recognition technology. Expense data in bank statements and invoices gets processed much faster through the employment of optical character recognition for the early identification of fraud and seamless transactions.
Healthcare
OCR is widely used in the medical world, as it processes patients’ medical records, extracts medical prescriptions, and processes and pays for insurance claims directly into the electronic health record system. It reduces the paperwork load and makes patient details more secure while allowing medical professionals instant access to vital information.
Retail and E-Commerce
Retailers and e-commerce websites make use of this technology for receipt recognition processes, so as to be able to automate the capture of expenses, invoice processing, and inventory management. It also helps in scanning barcode data and product labels for the effective management of stocks.
Legal and Government Documentation
In making contracts, legal documents, and official records, OCR is employed in digitising spaces in various government agencies and law firms. Now, with the technology of OCR, searching and archiving legal documents would be easy since all would be in digital format. Hence, no more hassles of filing everything in cabinets.
Logistics and Transportation
OCR is critical not only in shipping but also in the supply chain and warehouse management. Scanning and processing of shipping labels, invoices, and bills of lading are performed through this technology, thus making logistics operations much smoother and error-free.
Types of OCR Technology
The classification of OCR technology may vary based on function and application.
Standard Optical Character Recognition (OCR)
This is one of the oldest forms of OCR and recognizes printed text from scanned documents. It works beautifully for standard fonts but fails rather miserably with handwritten texts.
Intelligent Character Recognition (ICR)
ICR is an advanced version for recognizing handwritten text. It utilizes AI and machine learning and, over time, ICR has learned different handwriting styles.
Optical Mark Recognition (OMR)
OMR technology is used to scan forms, surveys, and multiple-choice answer sheets to identify marks made by a user.
Magnetic Ink Character Recognition (MICR)
This technology is used in the banking sector for processing checks and other financial documents that contain characters printed in magnetic ink.
OCR Process
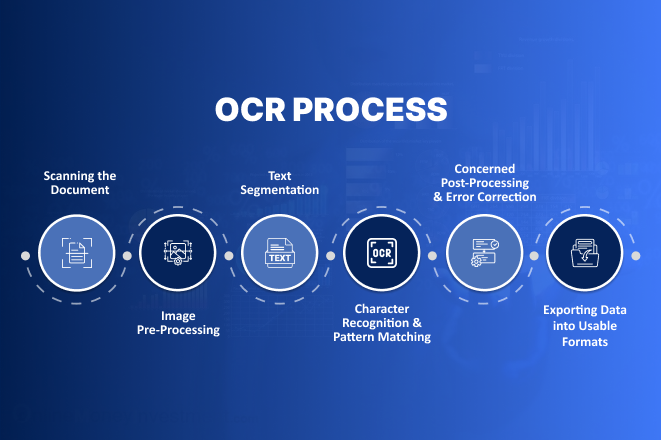
1. Scanning the Document (Image Acquisition):
An initial action of the OCR technology is to capture an image of the document to be processed. This may be done through a scanner, a mobile camera, an OCR machine, or specialized hardware for document processing. The scanned image directly affects the accuracy of the OCR; high-quality scans taken in contrasting colors and undistorted provide better results. Furthermore, a document can be acquired in various formats, like JPG, PNG, TIFF, or PDF, depending on the application. With the growing popularity of mobile OCR applications that let users extract data from receipts, invoices, and handwritten notes in real time, this whole process may now be performed from a smartphone.
2. Image Pre-Processing
With the scanning complete, the image would be manipulated for better legibility of the text in the document and hence a better recognition rate. Pre-processing techniques include binarization, eliminating noise, deskewing, and edge detection.
-Binarization is the conversion of the image into black and white such that the text can be discriminated from the background by OCR engines.
-Noise removal works for the unwanted stains, artifacts, and other disturbances potentially adverse to text recognition.
-Deskewing aligns with recognising the tilted or misaligned text from document scans.
-Edge detection locates boundaries between text and images so that OCR software can work solely on text finding.
The whole pre-processing sequence is therefore essential in maintaining efficiency because such processes will reduce the recognition errors that poor-quality images bear.
3. Text Segmentation (Identifying Characters & Words)
Now that the image is pre-processed, OCR software examines it, pulling out the sustenance text from all other stuff. The recognition of lines of text, single words, and characters is then targeted. Segmentation is an essential step because erroneous [illegible] text detection would produce erroneous recognition results. Advanced OCR solutions are now trained using machine learning and AI-based algorithms to segregate text from graphics, tables, or handwritten notes.
For example, in the case of an invoice, segmentation ensures to the software that vendor names are separated from invoice numbers, item descriptions, and total amounts to avoid misinterpretation of data.
4. Character Recognition and Pattern Matching
At this point, the OCR engine identifies the characters, symbols, and numbers present in the segmented text. There are two major techniques used for recognition:
Pattern Recognition: The scanned text is matched against a database containing predefined character templates. This technique works quite well for standard printed texts but fails in the case of handwritten or stylized texts.
Feature Extraction: In this technique, instead of matching the whole character, the matching process is carried out on smaller components of the characters, such as the presence of strokes, loops, and intersections. Then the system uses knowledge of these features to arrive at the best probable match below the set of characters, hence allowing further recognition of acid with different fonts as well as handwriting.
Deep learning models are being employed in state-of-the-art OCR systems, winning evolved recognition by exposing themselves to fonts, languages, and styles of handwriting.
5. Concerned Post-Processing and Error Correction
Once the text extraction is done, the OCR engine carries out some post-processing treatment to ensure that recognition errors are corrected and accuracy is improved.
For instance, spelling and grammar checks assist in correcting falsely recognized words by either validating against a standard dictionary or an industry dictionary.
At the same time, context analysis done by AI and Natural Language Processing (NLP) may help the OCR to figure out the meaning of the extracted text, thus reducing errors at the level of sentences and paragraphs.
Data structuring and formatting guarantee that the extracted pieces of information (for example, invoice number, date, and value) are organized in such a manner that proper transfer into a database or accounting system is less cumbersome.
It is to this extent that these operations really improve the quality of the PDF OCR output and make sure that businesses can rely on precise and structured data.
6. Exporting Data into Usable Formats
Finally, after processing and validation, the text is exported to an editable and searchable format. The most common formats for export are:
-XT, DOCX, RTF for word-processing.
-For structured data management, use CSV and Excel spreadsheets.
-For software application and API integration, there are JSON and XML.
-The original layout is preserved, yet full text search functionality is enabled from Searchable PDFs.
Such flexibility means the utility of OCR technologies in various sectors like finance, healthcare, legal documentation, and logistics, where accurate document digitization matters.
Future Trends in OCR Technology

1. AI-Powered OCR System with Enhanced Accuracy
Traditional OCR systems have limitations with the recognition of complicated texts, handwriting, and images of inferior quality. AI-based OCR makes use of deep learning and neural networks to keep augmenting its text recognition accuracy.
-AI systems can also learn from a variety of datasets, thus enhancing the recognition of different styles of handwriting, typefaces, fonts, or scripts, and even languages.
-Self-learning OCRs can adapt to changes in document layout over a period of time to minimize manual intervention for corrections.
-OCR with NLP integrated into it has the advantage of understanding the context associated with the text being extracted and, therefore, reduces errors in complex documents.
AI-driven OCR can achieve nearly 100% accuracy on text recognition, which significantly reduces the need for manual verification.
2. OCR Processing in Real Time
The OCR is evolving to facilitate real-time text recognition and instant data extraction instead of batch processing.
Real-time OCR is revolutionizing industries through mobile apps for expense tracking, AR devices for hands-free scanning, instant translation tools, and banking/logistics document verification.
The real-time OCR equipment is changing industries as it eliminates manual data entry and automates workflows.
3. Enhanced Handwriting Recognition (ICR – Intelligent Character Recognition)
One major hurdle in OCR has always been reading handwritten text. Intelligent Character Recognition (ICR) is a more sophisticated type of OCR that can analyze cursive and unconventional handwriting.
-Artificial intelligence handwriting recognition will allow various types of institutions to automatically process handwritten checks and forms.
-Legal establishments and government entities can digitize handwritten historical documents with very high accuracy.
-Signature verification enhances counter-fraud and authentication exercises.
ICR will make the digitization of handwritten documents as seamless as for printed text recognition, which will open up more opportunities for businesses and research institutions.
4. Multilingual Applications in International Schools
With multinational businesses operating in different countries, OCR transforms to cater to multiple languages and complex scripts.
-OCR today recognizes 200+ languages, including Chinese, Japanese, Arabic, and Hindi, which have an unmanageable character arrangement.
-AI-driven detection of languages and auto-translation allows an OCR system to process a multilingual document without a second thought.
-Global manufacturers can automate the document processing without being restrained by the languages, thereby increasing operational efficiency.
Multilingual OCR is, therefore, essential for legal work, global e-commerce, and cross-border business transactions.
5. Cloud-based OCR provides scalable solutions
Any organization, any size, may now use OCR to become more scalable, efficient, and affordable.
-Simple cloud OCR services (for example, Google Cloud Vision or Amazon Textract) allow the processing of document volumes without heavy infrastructure investment.
-Combining edge computing with OCR allows for rapid text recognition in IoT devices so there is no lag in processing time.
-Data protection compliance ensures that digitized documents use secure cloud storage for online accessibility.
Cloud-based OCR just makes it easier for a business to integrate OCR within its existing enterprise applications for further automation.
6. AI-Powered OCR for Big Data and Analytics
Almost every major area, like data analytics along business intelligence, now relies heavily on OCR.
-That is a task of making it possible for a business to take structured data off everything from invoices to contracts or even sometimes legal documents through AI based OCR so that it is able to make knowledge-based business decisions.
-Pattern recognition and trend analysis aid in assessing market insights from vast amounts of data.
-Institutions in finance or healthcare digitize a lot of material for purposes such as fraud detection and automated monitoring of compliance.
OCR and AI analytics combine for a unique transformation in terms of decision-making in an industry where data rules.
Conclusion
From its primitive character recognition beginnings, it has progressed into AI-powered document automation. The real future of OCR lies in real-time processing for enhanced handwriting recognition, multilingual, and cloud-based solutions.