


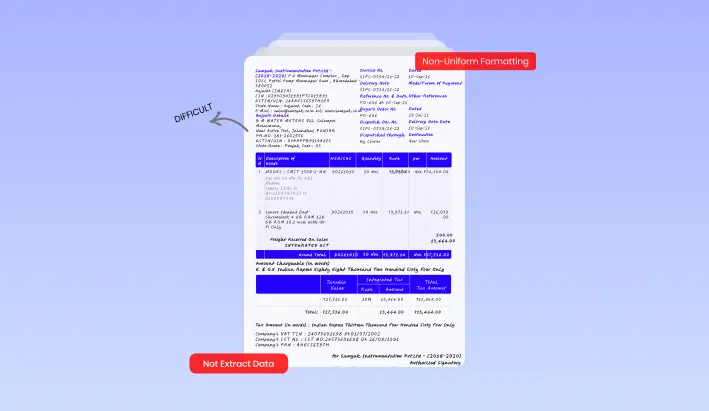
Non-Uniform Formatting
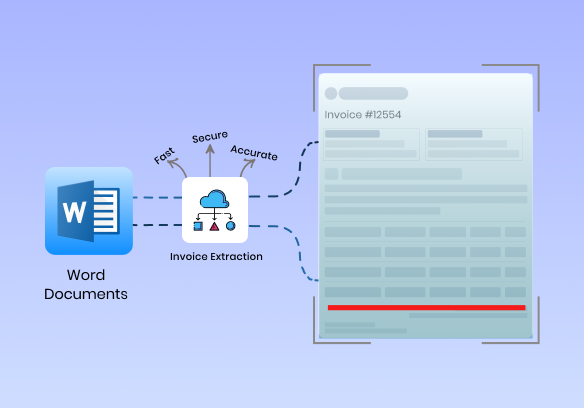
Business documents will contain different styles and formats on one hand, thereby making it difficult for any rule-based system to extract data from a Word document in any of such fields as invoice number, date, total, or customer, with any reliability.
Scanned or Handwritten Text in Word Files
Word-type documents in India abound with scanned pages or handwritten comments that require OCR for receipts also, or, in some cases, handwriting recognition for the extraction of digitised information.

Complex Layouts
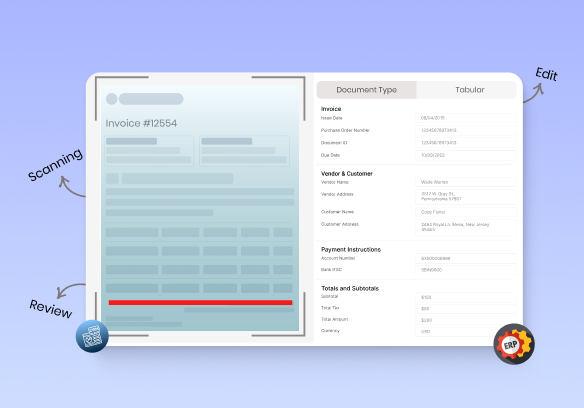
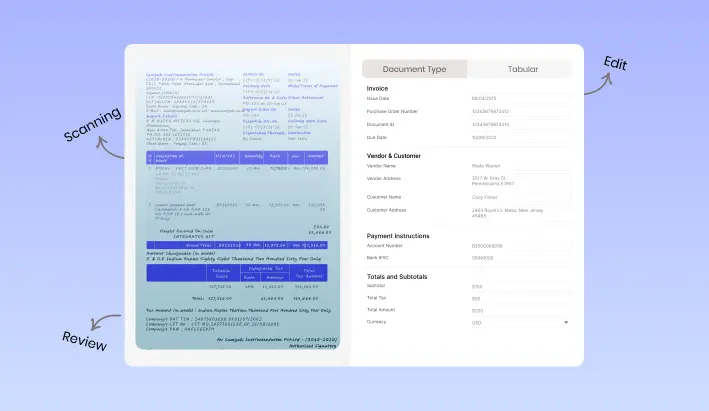
Word documents can have inconsistent metadata. They may also have complex layouts like multi-column texts, nested tables, or item lists. This can make it hard to extract data such as GST details, item prices, or tax breakdowns.

Content in Multiple Languages
The cultural diversity in the motherland adds to the barrier. The majority of documents carry content in Hindi, Tamil, Marathi, Bengali, or a combination of such regional languages with English, requiring language-sensitive extraction tools that allow processing in more than one language.

